コンピュータビジョン触ってるおじなので、色々論文を追っかけたりはしてるんですが、きっちりした理解をあんまりしていないものもあるので気が向いたときに復習兼ねてメモ書き残しておこうかなというアレ。
長くなるので3回ぐらいに分けようかと思います。
1. 論文概略
arXivへのリンク
画像の引用もこちらの論文から行っています。
2016年のYOLOと並ぶ物体検出の雄。
処理時間と精度のバランスが良いのと、FCN(全部がCNNで構成されている)ので入力サイズについても可変に出来て取り扱い易く、モバイル向けでは2022年現在でもつかわれています。
個人的にはYOLOよかは構成が素直で、カスタマイズするにもやり易そうということでSSDを読み直すことにしました。
2. なぜ今更古い論文を読むのか
2012年以降のコンピュータビジョン界隈でのディープラーニングの流れの中、
初期はモデルの構造が「こういうネットワーク構造にすればこういう特徴量が得られるはずだ」という特徴量デザインの観点から設計されているものが多かったと思います。
対して2018年以降ぐらいからは対照学習の様な「どういう構造にすれば上手く学習できるか」といった学習のさせ方を改善する目的のモデルが多いように思われますし、最近もベースは古来のネットワークを利用してそれに学習法を工夫したフレームワークで学習させるものが多いと感じています。
ということで、ディープニューラルネットワークによる特徴量デザインの観点でモデルの作り方を見直したいなと思ったので、古い論文を掘り返しています。
いや、高々6年前を古いと言っちゃう辺りここ最近の流れの速さを感じてします。
この界隈では結構高齢の方も現役でバリバリなされているので歳は言い訳に出来ねぇ…。
マジ、魔法の世界っス。大魔導士様様がいっぱい現存している社会です。でも、魔女狩りだけは勘弁な!
3. Single Shot MultiBox Detector の名前の由来
Single Shot : 画像からこのネットワーク1本でEnd to Endの推論/学習が実行できる。
MultiBox Detector : 特徴量マップ上にターゲットとなる矩形を配置して各矩形が何を検出しているかを推論する。
4. ネットワーク構造解説
論文中のFig.2をベースにネットワーク構造を解説して行きます。
4.1. 全体構成
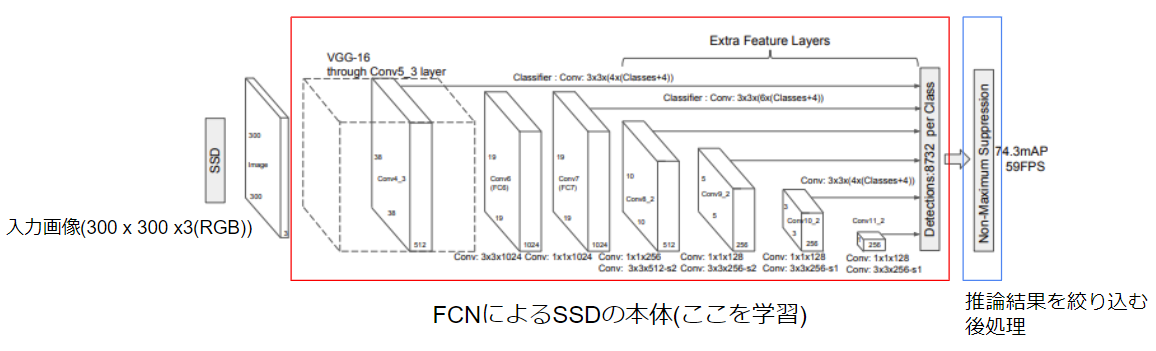
全体構成はめちゃくちゃシンプルです。
徐々に解像度を下げなら特徴量マップを作成し、各解像度の最終段の特徴量マップから場所ごと物体検出推論を行っています。
これが全部CNN(FCN)で行われているので、パラメータ数が抑えられ高速に演算可能となっています。
また、CNNのみで構成されているということは平行移動に対してはロバストであるため、物体検出というタスクには非常にマッチしています。
このCNN層の出力は各解像度マップ上の各点において「どのクラスの物体があるかどうか」が出るので、物体の総数としてはめちゃくちゃな数が出ます。
これを後処理で絞り込んで「物体っぽい物」だけを残すようにして実際には使用します。
4.2. 本体(FCN部分)

4.2.1 Classifier
の数に関して説明します。
の部分が物体特徴量を検出するのに使う
のConvolutionフィルタの個数になります。
より厳密に言えばConvolutionフィルタの次元はtex: 3 \times 3 \times kです。
ここに出てくる各変数について説明します。
:
各注目点(特徴量マップ上の各画素)について割り当てられた候補矩形の数。
:
仮の候補矩形毎の画像分類結果(nクラスの画像分類と同じ形)。
:
仮の候補矩形毎の正解矩形との差分を表す回帰パラメータ(位置(水平,垂直)で2次元, サイズ差分(縦横)で2次元で計4次元)。
に関しては正確に形状をとらえるのが難しそうな最高解像度である①と、逆にアップで見切れている可能性が大きそうな解像度の低い側の⑤, ⑥については4種類。
②~④の画像中の物体として我々がカウントしそうな中間サイズについては6種類の矩形候補を割り当てているようです。
これに関しては特に違和感ない設定になっていると思います。
また、1つの注目点につき複数(本モデルのケースでは4~6)の矩形が割り当てられることで、物体が画面上で交差しているケースでもその両方がとらえられるであろうことは分かると思います。
また図のパラメータで計算すると
と右端の検出数と一致することから、3x3のConv演算を行う際に外周に当たるpixelについてはなんらかのpadding処理をしているということが分かります。
4.2.2 CNNによる特徴量抽出の理解
このフィルタを使って物体検出をするということを局所に切り出して考えます。
ここでは、へ入力される特徴量マップのチャネル数は
と置いて説明します。
1つののフィルタによるConvolution演算は注目点を中心とした
の特徴量に対して、全結合層で1つの特徴量を算出することと等しく。
これを個のフィルタで行い
個の特徴量を抽出する、ということに等しいと言えます。
ただし、CNNはこのConvolution Filterが特徴量マップ中でのすべての場所で共通で使いまわされるのがポイントで、使いまわされることで最適化時に空間的な統計情報が盛り込まれます。
これにより(平行移動に対して)位置不変な特徴量が獲得できる構造となっています。
別の言い方をすれば、
のConvolution層の演算と、入力画像を位置を1pixelずつずらしながら
のサイズの画像にバラバラに切り分け、それらを画像バッチとして入力し、全結合層で
次元の特徴量を抽出する事は同じ操作になります。
4.2.3 物体検出特徴量の最小単位
SSDでの分類特徴量の最小単位は候補矩形でその次元は となります。
4.2.3.1 分類特徴量
は分類したい画像クラス毎の確からしさを表す特徴量です。
1つ注意点を挙げるとするならば、探している物体が見つからなかったことを表すためにその他に相当するクラスを追加する必要があります。
分類したいクラス数が個ある場合は
となります。
例) 画像中から犬, 猿, 雉を見つける物体検出器を見つけたい!
は犬, 猿, 雉, その他 の4クラスとなるので次元数は4となる。
その他クラスの学習のされ方については、その他の物体を一緒くたにしてまとめてちゃんと学習できるのかという問題はありますが、見つけたい物体以外を切り離すことで、見つけたい物体の学習がちゃんと出来る効果は見込めそうです。
4.2.3.2 矩形差分特徴
は対象の物体をピッタリ囲む矩形と、仮に設定した候補矩形との差分を出力する回帰問題の特徴量です。
この問題を図示すると次の様になります。

この図では3x3の解像度の特徴マップ上で、中心の領域に対する検出した物体の矩形領域の推論について説明します。
まず、矩形をその中心座標と幅、高さ
の形式で表現します。
学習の目標は推定矩形を正解矩形
に一致させることです。
SSDではのパラメータを直接的に推定するのではなく、注目点毎に毎に設定された基準矩形
からの差分を学習させます。
具体的には
と表現し、は固定で
を学習させます。
このようにすることで推定矩形の探索範囲が注目点付近の矩形に落ち着くようになります。
なお、実際にははその中心が注目領域の中心で、サイズとアスペクト比で4~6のバリエーションを持つ矩形として設定されます。
論文中のFig.2に記述されているClassifierのはここで設定している1か所辺りの基準矩形のバリエーション数に相当します。
5. まとめ
SSDでは物体検出問題を局所毎に切り出した画像領域のクラス分類問題 + 正解矩形と基準矩形との差分の回帰問題 の形に綺麗に落とし込めているのが分かると思います。
次回以降では以下の残件について説明して行こうと思います
- 評価関数
- 後処理
- 学習時の注意点
次回「評価関数編」へ
==== ↓会社に置いておくと会話が弾むかもしれない本 ====
![コンピュータビジョン最前線 Winter 2021【電子書籍】[ 井尻善久 ]](https://thumbnail.image.rakuten.co.jp/@0_mall/rakutenkobo-ebooks/cabinet/1458/2000010591458.jpg?_ex=128x128 "コンピュータビジョン最前線 Winter 2021【電子書籍】[ 井尻善久 ]")
![コンピュータビジョン最前線 Spring 2022【電子書籍】[ 井尻善久 ]](https://thumbnail.image.rakuten.co.jp/@0_mall/rakutenkobo-ebooks/cabinet/3825/2000010923825.jpg?_ex=128x128 "コンピュータビジョン最前線 Spring 2022【電子書籍】[ 井尻善久 ]")
![コンピュータビジョン最前線 Summer 2022【電子書籍】[ 井尻善久 ]](https://thumbnail.image.rakuten.co.jp/@0_mall/rakutenkobo-ebooks/cabinet/9864/2000011229864.jpg?_ex=128x128 "コンピュータビジョン最前線 Summer 2022【電子書籍】[ 井尻善久 ]")
![コンピュータビジョン最前線 Autumn 2022【電子書籍】[ 井尻善久 ]](https://thumbnail.image.rakuten.co.jp/@0_mall/rakutenkobo-ebooks/cabinet/3876/2000011833876.jpg?_ex=128x128 "コンピュータビジョン最前線 Autumn 2022【電子書籍】[ 井尻善久 ]")